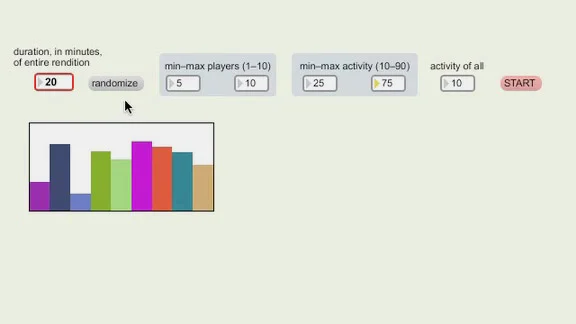
An eventual goal of Vir2Ual Cage was to develop a cumulative performable archive containing multiple video recordings of all 90 “solos for voice” in Song Books, realized by different performers in various contexts, infinitely combinable via chance operations. To assemble a particular performance, a listener/viewer would select a duration and possibly a few other parameters, then activate a computer program that would generate a unique rendition streaming on the Web. While this goal drew considerable interest, and the software underlying it was demonstrated as a proof of concept, by 2014 progress was suspended indefinitely due to a lack of support.
Below is an explanation of how renditions of Song Books would be generated from the archive of recordings. Included are some brief sample renditions composed of mock-ups instead of actual pieces from Song Books. The descriptions of the software’s algorithms encounter some issues that pertain specifically to Vir2Ual Cage but also generally to interpreting Song Books, thus offering insights into how renditions might be constructed without software, actually as well as virtually. This text first appeared as two blog posts written in November 2012 by Vir2Ual Cage team member Mark Bobak, who developed the project’s software in the programming environment Max.
Generating Renditions of John Cage’s Song Books from a Performable Archive

Part 1 of 2
John Cage’s general directions to Song Books are found in the score on page 1 of Volume I and page 218 of Volume II. Any number of performers may perform any portions of any of the work’s 90 “solos for voice,” in any order. (Note that every piece in Song Books is subtitled “solo for voice,” whether or not it calls for vocalization.) Any solo may recur in a given performance. Superimpositions are allowed; in some cases, a performer may perform more than one solo at a time. Each performer “should make an independent program, not fitted or related in a predetermined way to anyone else’s program,” to fit an agreed-upon performance duration. “Any resultant silence in a program is not to be feared. Simply perform as you had decided to, before you knew what would happen.” In Vir2Ual Cage, these directions are incorporated into software that assembles and executes unique renditions of Song Books in real time, extending Cage’s work in a way that he himself might have done were he in today’s world, with today’s technology.
Making Choices
At the core of Vir2Ual Cage is a performable archive that contains video or audio recordings of individual solos that are stored in a database in which they are tagged according to their type (song or theater), their relevance to Cage’s overall subject in Song Books “We connect Satie with Thoreau,” whether they include electronics, and such other attributes as their principal compositional method or direction to the performer; what text, if any, they incorporate; their relation, if any in particular, to Cage’s previous compositions; and their duration, their performer’s name, and the date they were added to the archive. These database tags, or metadata, allow a user to delimit the large pool of solos from which a rendition of Song Books is generated. The database was built using the relational management system SQLite embedded in the programming environment Max, and a user interface built with JavaScript.
The tags correspond to classifications in these documents, created by Jacqueline Bobak and Mark Bobak, which categorize all 90 solos and comment on how they are related. It should be noted that a definitive taxonomy of the many types of pieces in Song Books is problematic. The collection is remarkably diverse; it includes over 50 types of pieces or styles, depending on how such things are counted. Moreover, some pieces overlap in their compositional approaches or materials, directions to performers, or relations to Cage's previous pieces.
In any case, actual performers of Song Books may of course choose solos to perform based on various criteria beyond aesthetics, including such practical considerations as voice type, physical capability, or technical difficulty. But “virtual performers” are not constrained by such factors. In Vir2Ual Cage, virtual performers are in fact software modules, built using Max and QuickTime, that play movies of solos. Their “repertoire” encompasses every recording of every solo in the archive, available at a moment’s notice. It is important to note that these virtual performers do not correspond to actual performers whose recordings they play. They are essentially projectors that start and stop playing movies according to directions from other software modules. Each movie player can play only one movie (and thus only one solo) at a time, but several (currently up to a dozen, depending on computing resources) independent movie players may play simultaneously.
Choosing the entire archive, which is the default option, makes all recordings of all 90 solos available to be played. But by querying the database, a user may arbitrarily limit the pool of solos, for example to those classified as songs that include electronics, are relevant to connecting Satie with Thoreau, and include text. As it turns out, 12 solos fit these criteria. (The number of solos that fits a query—and also the number of recordings, which is not necessarily the same, since there may be more than one recording of any solo—is reported after each query.) For another example, a user may limit the pool of solos to those in the category of theater that exclude electronics, are irrelevant to connecting Satie with Thoreau, and exclude text. Fourteen solos happen to fit those criteria. For yet another example, seven solos happen to fit the criteria of songs that include or exclude electronics, are relevant or irrelevant to connecting Satie with Thoreau, and are of the compositional type “cheap imitation.”
Another option available to the user is to select individual solos by their numbers. This ability to arbitrarily and precisely specify which solos are in the pool transforms Vir2Ual Cage into an exploratory tool that can allow a user to compare different renditions of the same solo, or design renditions that are focused thematically, for example consisting only of solos that invoke Thoreau, or only those that include text from his Journal, or only those that feature a certain compositional device. Thus the user may become a sort of director who can influence the content of a performance, although not the details of its presentation.
Apart from defining the pool of available solos, the user also must determine the rendition’s duration. All other parameters may be left at their default settings, but duration is the one parameter that explicitly must be chosen. For the time being, the minimum duration is two minutes and the maximum is one hour, but software tests suggest that renditions could last several hours, or even days. The upper limit depends largely on computational capacity. Thus Vir2Ual Cage may be suitable for such greatly extended presentations as continuously running installations in museums.
Making Scores
Once the pool of solos is defined and the duration for the entire rendition has been set, another software module—like the others, built using Max—generates the performing program, as Cage calls it. Herein we refer to this program as a “score,” a plan of activities to be followed during performance, a term that avoids confusion with “program” and “software.” Though Cage does not specify how to proceed, his methodology and predilection, as well as significant compositional decisions in Song Books, strongly encourage the use of chance procedures. But even with chance procedures, various decisions must be made, since the context in which indeterminacy is used is crucial to the results it obtains.
In Vir2Ual Cage, an aleatoric algorithm constructs a score for each virtual player—each software module that plays movies—according to adjustable parameters. The main parameter is the degree of activity in a performance, its overall density, which depends on two factors: the number of movie players that are available, and the percentage of time that each player is active. The minimum and maximum number of movie players currently is one and twelve; the upper limit depends on computational resources. Although Cage’s instructions mention a lower limit of “two singers,” single-player renditions are possible in Vir2Ual Cage partly because of its dual function as a research tool and partly because the performance history of Song Books seems to justify them despite their muting the work’s social aspects. The minimum and maximum activity levels for each player range from 10 to 90 percent (the reasons why the upper limit is short of 100 are given below, under “Some Technical Details”). All these parameters can be set manually or randomized within their minimum and maximum values. A graphical user interface indicates how many players are active and what percentage of time they will play. Since this is much easier to see than describe verbally, below is a short video illustrating this part of the user interface, which is currently in a simple preliminary version for testing purposes.
Once the number of players and their levels of activity are set, the next step to generating a performance is to engage another software module that makes the scores. These scores are data files with lists of numbers that contain instructions for yet another module that activates when the performance begins. The score-making algorithm writes a data file for each movie player in turn, until there are as many score files as there are movie players. As with live performers, each score is independent of the others, although in this case the same method is used for each player, whereas live performers may use various methods. In the future, the score-making procedure described below may be supplemented by others.
The score-making algorithm in Vir2Ual Cage proceeds by choosing a movie randomly from the pool of possibilities, then placing it randomly in a randomly chosen available segment of time in the entire duration of the rendition. Before the first movie is placed, the entire duration constitutes a single available segment. As specified durations of activity are filled, the available segments become shorter and more numerous, and the unoccupied durations into which subsequently chosen movies can be placed become progressively more fragmented.
For example, suppose that a given movie player is to be active 50 percent of the time during a rendition that has a total duration of 20 minutes. This means that this player must play 10 minutes of content, not necessarily contiguously, somewhere during the 20 minutes. Suppose the initial movie chosen has a duration of 5 minutes. Since 10 minutes are available, and must be filled, the entire movie can and will be played. Note that each solo in Song Books may be performed “in whole or in part.” Regardless of how much of a solo’s material was performed in a recording, the algorithm will attempt to play the entire recording if possible, placing it so that it will fit into the available segment.
If the movie’s duration exceeds that of the available segment, the algorithm will truncate the movie, choosing randomly from among four possibilities: 1) start at the movie’s beginning and stop before the end; 2) start at some time point after the beginning and stop at the end; 3) play the middle of the movie, leaving equal durations unplayed at both the beginning and end; or 4) start at a random point from the beginning, and stop at the appropriate point later. Note that the actual recorded movie itself is not truncated or otherwise edited; the word “truncate” here refers only to determining starting and stopping points within the movie.
If time remains in a segment after a movie is placed within it, that remaining time—probably in two segments, one before the just-placed movie and one after it—will be available for the next movie to be placed. Suppose, for example, that the 5-minute movie is placed to start playing 3 minutes into the rendition. After its stopping point at the eighth minute, 12 minutes will remain in the rendition. Thus, two segments will be available: one 3 minutes long, the other 12. Now 5 minutes remain to be filled in order to complete the requisite 10 minutes of activity for this player. Segments shorter than about 10 seconds, however, are discarded for technical reasons discussed below. So far, the movie player in question will be inactive for 3 minutes, then play the entire 5-minute movie, then be inactive again for the remaining 12 minutes. This example may be represented graphically as follows. Time points are indicated in minutes, and the red line indicates where the movie has just been placed.

The preceding process is now repeated. But this time, instead of treating the rendition’s 20-minute duration as one segment, the algorithm chooses randomly from the two available segments, which are 3 and 12 minutes long. Suppose it chooses the first segment of 3 minutes, which happens to correspond to the beginning of the rendition. Suppose further that the next movie chosen happens to be 15 minutes long. While 5 minutes must be filled, only 3 minutes are available in this segment, and so only part of the 15-minute movie will be played, its starting and stopping points determined according to the truncation method described above. The entire 3-minute segment has been filled, resulting so far in 8 minutes of playing time, and leaving 2 minutes yet to be filled. Had the other, 12-minute segment been chosen, 5 minutes of the movie would have been able to fit, thus adding up to the requisite 10 minutes, finishing the task of filling this movie player’s time and proceeding to make a score for the next player, if there is one. The score-in-progress is represented graphically below. The red and green lines indicate where the first and second movies were placed respectively.

Having 2 more minutes to fill and only the remaining 12-minute segment in which to do so, the algorithm continues by randomly choosing another movie. Suppose this movie’s duration is 6 minutes. Though the entire movie could fit into the 12 available minutes, only 2 minutes of it will be played, once again according to the truncation method described earlier. Suppose a 2-minute portion of this movie is placed randomly at a point 3 minutes into the 12-minute segment, a point that corresponds to the eleventh minute of the 20-minute rendition. Thus the requisite 10 minutes of activity have been filled, and the other 10 minutes of the rendition are “empty.” The finished score is represented graphically below. The red, green, and blue lines indicate where the first, second, and third movies were placed respectively. Smaller colored numbers indicate the durations of occupied and vacant segments, which add up to 20 minutes.

Note that the score-making algorithm relies significantly on chance; it chooses movies randomly, places them into the rendition randomly, and determines their starting and stopping points randomly within certain parameters. Note also that movies and vacant segments of time are not necessarily contiguous, nor are they determined linearly from the beginning of the rendition to the end. The longer the duration of a rendition, and the shorter the duration of movies chosen to fill it, the more fragmented a player’s active segments are likely to be.
This algorithm represents but one approach to constructing scores. Different algorithms may be expected to yield different yet potentially equally valid results. For example, another approach might be to divide in advance the duration of a rendition into segments of equal or unequal lengths, and randomly choose the beginning times of these segments as points at which solos will begin. In such a case, a score might be considered “finished” when some predetermined duration, perhaps expressed as a percentage of the entire duration, was filled. Alternatively, a score might be considered “finished” when all the solos in the pool of choices, or a certain subset of solos, are included in the performance, their durations being adjusted somehow as necessary.
Some Technical Details
It was mentioned above that vacant segments shorter than about 10 seconds are discarded from the pool of those that may be filled. A related detail about segments, omitted from preceding examples for simplicity’s sake, arises when two movies are placed adjacently. In fact, the score-making algorithm defines segments such that they are separated by a few seconds—currently 6, though this figure is adjustable, depending on computing resources—in order to allow time for movies to be read from a hard disk before playback. This means, in the preceding examples, that the first two movies placed (represented by the red and green lines in the graphs) would actually be separated slightly, allowing the software a gap of a few seconds in which to stop playing one movie, load the next movie, and begin playing it.
Gaps between segments have a further effect on making scores. In the earlier description of the user interface, minimum and maximum values for the level of activity per player were set at 10 and 90 percent respectively. The lower limit of 10 is arbitrary, analogous to a reposeful live performer who is active during only 6 minutes of every hour. The upper limit of 90, instead of 100 or some other figure, has to do with the facts that vacant segments shorter than 10 seconds are discarded, and gaps are left between otherwise adjacent segments. Thus it is impossible for a movie player to be active 100 percent of the time (not to mention challenging for a live performer in a long rendition). Experiments with upper limits of 93 or 95 percent show that these are possible but impractical because they destabilize the score-making algorithm. Note that this is the case only for a single movie player; among multiple independent movie players, any number of juxtapositions or simultaneities may occur, just as among independent live performers.
Activity graphs, such as those below, can show when each movie player plays in a rendition, allowing comparisons of different results obtained by running the same algorithm again and again. Such graphs are intended here only for illustration or debugging. They probably will be excluded from the final user interface in part because their revealing in advance “what will happen and when” might diminish the serendipitous unpredictability that characterizes most performances of Song Books—in other words, “spoil the surprises.” The following 4 graphs show 4 sets of results from setting each of 9 players all to the minimum level of 10 percent. Each player is represented on the vertical axis by a different color. Time is represented along the horizontal axis, scaled to the rendition’s total duration, which in this case is 20 minutes. Note that these graphs show only which movie player is playing and approximately when, not which solos are being played.




Note the considerable and unpredictable intervals of silence or inactivity, including at some renditions' beginnings and ends, which may even be obscure to an observer. This is perfectly acceptable in Song Books; as Cage writes in the directions, “Any resultant silence in a program is not to be feared.” Another set of graphs below shows four different sets of results from running the same algorithm to generate scores for 7 players, all of whom are active 40 percent of the time, again for a duration of 20 minutes. As expected, this time the resulting renditions are much denser. There are times when only one or two players are active, but only a few brief passages of complete silence or inactivity, barely noticeable at some beginnings and ends.




The final step in generating a performance is to engage another software module that reads these scores, directing movie players to start or stop playing and positioning movies on the visual canvas of a computer monitor. In the next post, additional graphs will be followed by sample renditions of Song Books comprised of “dummy” movies, substitutes that represent performances of solos but were constructed for testing. This may be a good time to conclude with the admission that such mock-ups remain necessary partly because we still lack recordings of a complete set of all 90 solos. Since we imagine that a reader who has persisted until the end of this post is likely to be genuinely interested in our project, we renew our invitation to such a reader to contribute recordings to Vir2Ual Cage’s performable archive.

Part 2 of 2
Part One discussed the performable archive at the core of Vir2Ual Cage, and how the project’s score-making algorithm will generate renditions of Song Books. Part Two discusses how such renditions are presented or “staged,” and includes a few samples comprised of “dummy” movies, rudimentary substitutes that represent performances of solos but were constructed only for testing purposes.
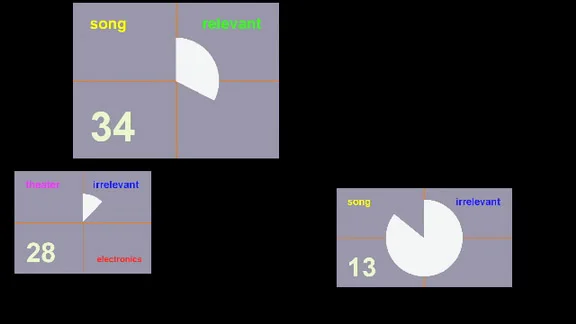
Ninety dummy movies, one for each solo, are tagged with the same information as movies of actual solos in a dummy database that functions identically to the real one. Each movie consists of a circular graph that advances clockwise, filling a pie shape as the movie plays, and includes text that identifies its type (song or theater), whether it includes electronics, and whether it is relevant to Cage’s subject in Song Books “We connect Satie with Thoreau.” The movies’ durations follow a pattern: the first ten movies (solos 3–12) are one minute long, the next ten (solos 13–22) are two minutes long, the next ten (solos 23–32) are three minutes long, and so on until the last ten (solos 83–92), which are nine minutes long. An example may be much clearer to understand than a verbal description; below is the dummy movie of Solo 25, which lasts three minutes. (Note that in Song Books, solos are numbered from 3–92 instead of 1–90 because Cage composed solos for voice 1 and 2 in 1958 and 1960 respectively, separately from Song Books.)

Instead of music from Song Books, the dummy movies contain other music, composed chiefly by John Cage or for the most part related to him, from recordings that happened to be conveniently available in the programmer’s music collection. As with the movies’ durations, each set of ten movies contains a different audio track, as listed below according to composer, title, and performer.
solos 3–12: Cage, Mureau (John Cage)
solos 13–22: Cage, Imaginary Landscapes and Credo in US (Percussion Group Cincinnati)
solos 23–32: Cage, Sonatas and Interludes for Prepared Piano (Philipp Vandré)
solos 33–42: Cage, Apartment House 1776 (Arditti Quartet)
solos 43–52: Mark Bobak, Football Mix (realization of Cage’s Fontana Mix)
solos 53–62: Cage, Roaratorio (voice, several Irish musicians, and tape)
solos 63–72: Morton Feldman, For Bunita Marcus (Stephane Ginsburgh)
solos 73–82: Brian Eno, Thursday Afternoon (Brian Eno)
solos 83–92: Cage, 103 (Orchestra of the S.E.M. Ensemble)
Further technical details may be discussed in subsequent writings, but for now note that these dummy movies were designed to strike a balance between visual quality and computational efficiency on relatively modest hardware. Their dimensions are either 640 x 360 pixels (for odd-numbered solos) or 480 x 360 (for even-numbered solos—the software can play movies of any aspect ratio), and they were recorded at 30 frames per second using the Photo-JPEG codec at about 75% quality. Tests with larger sizes and other codecs, such as Apple ProRes 422, show that significantly higher quality is attainable, depending largely on computing hardware. So far, the hardware/software combination can play at least 10 test movies simultaneously. Of course, given continued technological advances, it seems likely that quality, as well as the number of movies that can be played simultaneously, can be increased considerably in the near future.
Staging Song Books
Among the many questions that performers of Song Books must answer—in addition to what solos to perform, how, for how long, and when—is the often overlooked question of where. In keeping with its connotation of merging art with life, Song Books is especially amenable to being presented in venues other than traditional concert halls, and offers rich possibilities for creatively utilizing alternative performance spaces. But in contrast to a traditional theatrical piece in which a director “stages” a production, performers of Song Books are expected to determine their own locations and actions. Such autonomous decision-making, despite its often unpredictable results, is in fact an important if controversial aspect of Cage’s piece. As with other parameters of Song Books, staging also may be determined by chance operations and incorporated into software.
Coexistence among diverse performers, and the social conduct it represents, is a cardinal premise of Song Books. In a physical performing venue such as a theater, performers are supposed to amicably resolve potential conflicts caused by inadvertently trying to occupy the same spaces at the same times. In fact, rehearsals of Song Books often are held largely to identify potential collisions or obstructions, as exercises in traffic control rather than interpretive refinement. In a virtual space such as a computer monitor, several options exist for avoiding collisions among visual objects. Similar issues are encountered commonly when programming collision detection algorithms for video games, physical simulations, or robotics.
In Vir2Ual Cage, a prevailing objective when playing movies is that they all be at least partly visible to an observer for the majority of their assigned playing time. This objective parallels the principle of “coexistence without interference” among live performers. Of course audibility also is important, but poses relatively trivial technical challenges compared to video (see below). In the software’s current implementation, all movies are positioned such that they appear somewhere on a single window having a ratio of 16:9 (1.777:1), a standard “wide screen” televisual format. Other possibilities are easy to imagine, but progressively more difficult to implement: multiple monitors, projections onto alternative surfaces, or even complex immersive environments limited largely by technological considerations.
The staging algorithm determines movies’ sizes and positions on the screen largely according to chance procedures. It is a separate software module for purposes of efficient and flexible design rather than conceptual distinction. It operates in real time, making decisions “on the fly” as the performance unfolds, which is notably different from most other decisions that are made in advance by other software modules. Were a rendition of Song Books using the same set of score files repeated (which is possible, but currently only for testing purposes), the same movies would start and stop at the same times, but their sizes, positions, and transitions (entrances and exits) on the screen would be different each time. An example presented later in this discussion demonstrates this very situation.
In Vir2Ual Cage, each movie-playing software module is associated with a corresponding video plane in three-dimensional space. These video planes are then composited in a drawing context and rendering destination (essentially the computer monitor) using the OpenGL specification (Open Graphics Library), which exploits possibilities for accelerating calculations that define scaling (movies’ sizes), blending (degree of transparency), rotation (movement around an axis), and other parameters. As the score files that specify starting and stopping points of each movie are “read” while a clock advances in real time, the staging algorithm proceeds by randomly choosing values for the following parameters from between mimimum and maximum limits:
• scale:
the movie’s size on the screen. In the examples below, the minimum and maximum scale ranges from 20 to 60 percent of the full size, which would fill the entire viewing window. The software maintains movies’ original aspect ratios, using “letterboxing” or “pillarboxing” where necessary to avoid possible horizontal or vertical distortions (cropped or stretched width or height).
• entrance:
the method and rate of the movie’s initial appearance on the screen. In the examples below, the method is limited to a fade from a black background via alpha blending (see below), and the rate is chosen randomly from a minimum of one second to a value no more than 20 percent of the movie’s assigned duration—not necessarily its total duration, which may be truncated. Future implementations may include, for example, entrances in which movies gradually increase in size to their destination value, change their position, or begin playing off-screen.
• position:
the movie’s location on the screen. In the examples below, the position of each movie is determined randomly after taking into account its scale, so that its entire rectangle will fit on the screen. The randomness is weighted so that movies are placed more often into quadrants on the screen, thus reducing their potential for collisions with other movies. When a movie occupies a certain quadrant, the algorithm tends to position the next movie randomly in an unoccupied quadrant. Sometimes, especially when more than four movies are playing, the algorithm renders a movie semi-transparent (see below) in order to facilitate the visibility of superimposed movies.
• alpha blending or transparency:
the degree to which a movie’s colors are combined with a black background. In the examples below, the blending amount ranges from zero (the movie is completely transparent, thus invisible) to one (the movie is completely opaque). Blending currently is implemented to occur mostly under two circumstances: first, when a movie fades in or out as it enters or exits; and second, when a movie’s position would cause it to obscure another movie. In the latter case, a movie is rendered semi-transparent when it is superimposed. Thus movies that are “in front” of others may be “seen through,” so that movies “behind” them are also visible. This is a rudimentary yet effective solution to the problem of interference among movies; it facilitates their perceptibility to the observer, even though movies that are in the background still may be obscured somewhat, analogously to live performers whose locations partially obscure them from the audience. Future implementations may include more sophisticated methods of collision avoidance. Multiple computer monitors offer still more possibilities for avoiding collisions.
• animation:
the movie’s change in position after its entrance but before its exit. In the examples below, this feature is not implemented. In the future, movies may change position on the screen, apart from their entrances and exits, somewhat like a live performer who changes his position on an actual stage. Other examples could include rotating movies on up to three axes (known in flight dynamics as roll, pitch, and yaw), or changing such parameters as scale or transparancy to unorthodox degrees. It should be noted that such staging techniques, while tempting enough to offer creative opportunities in their own right, may risk overtaking the movies they present. Indeed, similar issues have arisen with videography when recording solos from Song Books.
• exit:
the method and rate of the movie’s final disappearance from the screen. In the examples below, exits are essentially the opposite of entrances; their methods and rates are the same as described above under “entrances.”
Audio
As is typically the case in media programming, “staging” audio in Vir2Ual Cage poses much less of a challenge than video, both aesthetically and computationally. As with video, an underlying objective is that each movie be potentially audible, even though in practice its sound may be obscured by other movies. (Recordings in the archive that contain only audio are treated as movies that have “blank” video tracks.) Audio tracks, which are assumed by default to be stereo, simply fade in and out at rates commensurate with their movies’ entrances and exits; their volume is approximately commensurate with their scale; and their positions in the stereo field are approximately commensurate with those in the visual field. For example, a movie that appears at a scale of 20 percent will be played at a volume somewhat lower than a movie at 40 percent, though the difference will be less than a factor of two because amplitude is scaled to a range that tries to account for auditory perception. The sound of a movie that appears toward the left side of the screen will be panned toward the left channel. In no case is a movie’s volume attenuated or amplified significantly in comparison to that of other movies; in no case is a channel panned far enough to be inaudible. In fact, the original volume or stereo imaging of a movie’s audio content probably will have a much greater effect on its position in the soundscape than any decision made by the staging algorithm.
Some Examples
The following mock-up renditions of Song Books are preceded by illustrations similar to those in Part 1: bar graphs that show density settings according to which the scores for each movie player were generated, and activity graphs that show when movies start and stop playing. The first example presents a 10-minute rendition for 6 movie players, whose activity levels were randomized between 20 and 40 percent (the resulting percentages were 25, 31, 37, 21, 39, 28). Since this rendition is quite short for Song Books, its content is limited to short movies of solos 3 to 42, which range in duration from 1 to 4 minutes. Note the empty space on the activity graph below, and hence the minute of silence at the end of the rendition.


The second example repeats the same rendition as the first, except this time with a different staging, shown just to illustrate some other choices the staging algorithm can make. In other words, the same movies will appear at the same starting and stopping points as before (within the rendition as well as the movies themselves), but their locations on the screen will be different.

The third example presents a 15-minute rendition for 8 players, whose activity levels were randomized between 30 and 60 percent (this time the resulting percentages were 33, 46, 52, 48, 35, 47, 38, 31). This duration is still quite short for Song Books, but here the database was set to make the entire archive, all 90 solos, available. This means that the source movies range in duration from 1 to 9 minutes. By happenstance, an empty space appears again at the end of this activity graph, resulting in about 40 seconds of silence at the end of this rendition.



Some Observations
Silence
There may be considerable and unpredictable intervals of silence or inactivity (an empty black screen), including at performances' beginnings and ends, which may even be obscured. In Song Books this is perfectly acceptable, maybe even desirable; as Cage writes in the directions, “Any resultant silence in a program is not to be feared.” The density of a given performance is to some extent definable by the user, who can set parameters for the score-making algorithm. Whether a performance is to be sparse, dense, or anywhere in between may be a matter of preference, with all due respect to Cage’s desire to eliminate or at least reduce the effects of his personal tastes in his art. However, it seems often that the most aesthetically satisfying results are obtained—in live performances of Song Books as well as Vir2Ual Cage—when a significant degree of silence is at least potentially available, leaving “breathing space” rather than “filling up” the time. As an aside, long intervals of silence or inactivity—a performer on stage but apparently “doing nothing”—often prove surprisingly challenging for both performers and observers of Song Books.
Space
Activities on a computer monitor and pair of speakers tend to be perceived quite differently than when they occur in a much larger physical space, especially when the staging or soundscape is dense. In a small, relatively closed environment, everything seems more compressed or constrained than it does in a rather large, open environment wherein sounds can emanate from multiple points and activities may require an observer to move about in order to see them. A limited audiovisual space is a practically unavoidable consequence of the way Vir2Ual Cage operates at this time, although in the future, stagings may be broadened by multiple screens or multi-channel diffusion in larger spaces, lending them the character of an installation. Eventually, renditions may be recorded, and the recordings themselves may become part of the archive from which further renditions are generated. Indeed, the many creative options available for presenting Song Books illustrate the richness of the work.
Interest
At 10 or 15 minutes, these sample renditions are unusually short for Song Books. While no particular duration for a rendition is necessarily optimal, it seems from the Vir2Ual Cage team’s experiences of presenting numerous live renditions that those longer than about 30 minutes tend to be most successful. Longer renditions are more likely to allow activities to ebb and flow, illustrate the great diversity of the work, and offer a greater variety of gestures, soundscapes, and silences that many observers find interesting. Very long renditions—the Vir2Ual Cage team has twice produced live events lasting 4 hours—tend to take on the character of installations that may occupy larger spaces and encourage audience members to roam freely rather than remain seated. While this may not be an occasion to debate what may or may not be “successful” or “interesting” about performances of Song Books, the frequency with which this issue arises, among performers and observers alike, merits its attention in a further discussion. Until then, readers are imvited to contribute recordings to Vir2Ual Cage’s performable archive, in anticipation of presenting full-fledged renditions of Cage’s decidedly interesting work.